Máy tính trí tuệ tương lai – các hệ tính toán tự nhiên
Để giải quyết những hạn chế về hiệu quả tính toán và điện năng, trong tương lai, các máy tính AI sẽ phải dựa trên các cấu trúc gần với tự nhiên hơn, hay còn gọi là Natural Intelligence (NI).
Các ứng dụng trí tuệ nhân tạo (AI) hiện nay đang trở nên phổ biến và mang lại nhiều giá trị trong mọi mặt của đời sống. Tuy nhiên việc tính toán AI trên công nghệ hiện tại vẫn mang tính nhân tạo và kém hiệu quả về mặt năng lượng so với các hệ thống tự nhiên như não bộ của chúng ta. Hệ quả là thời gian tính toán AI, đặc biệt là phần học (training), rất lâu và tốn nhiều điện năng. Cùng với sự kết thúc của Định luật Moore (kích thước của mạch điện không thể nhỏ hơn được nữa) và nhu cầu tính toán AI tăng theo hàm mũ thì các hạn chế của công nghệ AI hiện tại sẽ ngày càng bộc lộ rõ. Do đó trong tương lai, các máy tính AI sẽ phải dựa trên các cấu trúc gần với tự nhiên hơn, hay còn gọi là Natural Intelligence (NI).
Nút thắt cổ chai ALU
Gần như tất cả các hệ thống AI hiện nay đều dựa trên các máy tính có kiến trúc Neumann (GS. John von Neumann – được coi như người phát minh ra máy tính). Ở đó mọi tính toán được thực hiện ở Bộ logic số học (Arithmetic Logic Unit – ALU) trung tâm (còn gọi là core), tách biệt khỏi bộ nhớ. Chỉ có một hay một số core trong máy tính và chúng tính toán mọi thứ. Hàng trăm, thậm chí hàng ngàn ứng dụng chúng ta đang chạy cùng lúc như xem ảnh, đọc báo, copy file, phát nhạc, kết nối với Internet, gửi mail,… thực chất được thực hiện nối tiếp trên các core này, mỗi thời điểm chỉ có một ứng dụng chạy trên một core. Sở dĩ chúng ta không cảm nhận được giới hạn này và cảm thấy như tất cả ứng dụng chạy đồng thời vì ALU chạy rất nhanh, vài tỷ lần chuyển mạch mỗi giây.
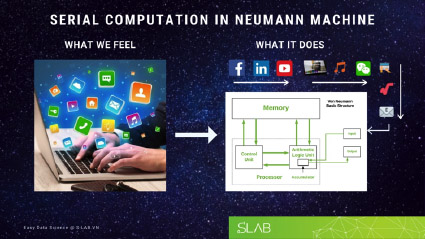
Hình ảnh 1: Hàng trăm ứng dụng có thể chạy cùng lúc trên một hoặc chỉ một số core (2, 4, 8)
Nhưng các ứng dụng AI thì không dễ dàng như vậy bởi khối lượng tính toán rất lớn. Ví dụ một mô hình AI mạng neuron có 10 triệu trọng số (không quá lớn) với 1 triệu hình ảnh mẫu sẽ có 10.000.000.000.000 (mười nghìn tỷ) đối tượng cần được tính toán. Hơn thế nữa, mỗi đối tượng phải được tính toán nhiều ngàn lần mới tìm được giá trị phù hợp. Điều này giống như mười nghìn tỷ bệnh nhân xếp hàng để khám, mỗi bệnh nhân phải khám hàng ngàn lần mới chữa xong, mà chỉ có một, hai hay bốn bác sĩ (ALU/core) mà thôi.

Hình ảnh 2: Các trọng số trong mạng AI giống như hàng ngàn tỷ bệnh nhân đợi khám, mỗi người cần khám hàng ngàn lần với chỉ vài bác sỹ (core, có thể là CPU hay GPU)
Kết quả là ngày nay, các bài toán AI chạy cả ngày lẫn đêm. Các nhà khoa học thì phải cắt bớt độ phức tạp của mô hình (do đó giảm hiệu suất) để giảm thời gian tính toán, các sinh viên thì ít khi nào có đủ phần cứng để chạy các mô hình AI mong muốn. Trong doanh nghiệp, các hãng khổng lồ như Google, Facebook có ưu thế vượt trội vì có trung tâm dữ liệu khủng. Và AI đang dần trở thành một ngành “công nghiệp” thực sự vì nhiệt lượng tỏa ra quá lớn. Tính toán nối tiếp qua ALU trong máy tính hiện nay dường như là một nút cổ chai trong thời đại AI.
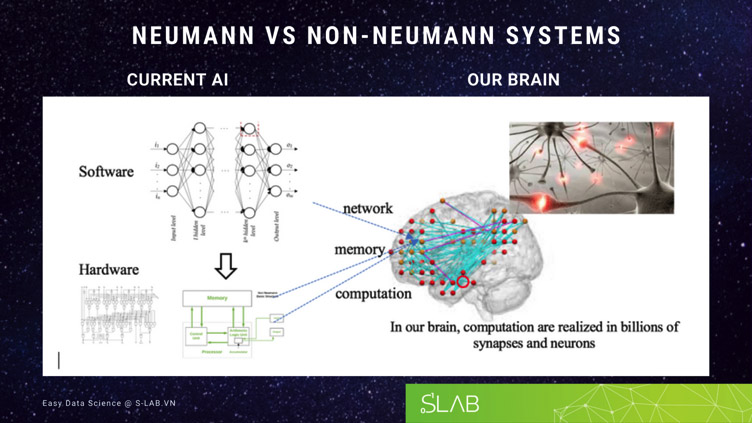
Hình 3: So sánh kiến trúc AI hiện tại với thiết kế mạng lưới ở phần mềm, tính toán ở phần cứng trên máy tính cấu trúc Neumann, so với não bộ có sự tích hợp giữa thiết kế mạng lưới, tính toán và bộ nhớ hoàn toàn trên phần cứng. Tính toán thực hiện ở mọi neuron và dây thần kinh.
Các hệ thống AI của tương lai do vậy cần có một kiến trúc khác, phi Neumann, làm sao cho tính toán có thể diễn ra ở nhiều nơi hơn nhiều trong hệ thống, tính toán khu vực ở mức độ linh kiện. Ví dụ: nếu một bộ xử lý có 1 tỷ bóng bán dẫn, thì phải có 1 tỷ đơn vị tính toán hoặc ít nhất vài trăm triệu. Lý tưởng nhất là mỗi bóng bán dẫn cũng có thể tính toán. Một kiến trúc như vậy sẽ tự nhiên hơn, giống như trong não của chúng ta tính toán diễn ra trên mọi nơ-ron và dây thần kinh. Một hệ tính toán phi tập trung như vậy (não của chúng ta hoàn toàn phi tập trung, không có bộ phận xử lý trung tâm) mới có thể thực hiện các tính toán AI hiệu quả được. Và hệ thống cần được thiết kế dựa trên các thành phần vật liệu nhỏ hơn, dựa trên các định luật vật lý cơ bản hơn, và trở thành các hệ thông minh tự nhiên.
Số hóa hay không số hóa?
Khoảng 70 năm trước đây, transitor điện tử bán dẫn lần đầu tiên ra đời đã tạo ra một cuộc cách mạng máy tính. Transistor là một thiết bị điện tử có thể chuyển mạch giữa hai trạng thái 0 và 1. Với 2 transistor và 3 điện trở chúng ta có thể tạo ra một cổng logic, ví dụ cổng NAND trong hình 2, là một đơn vị tính toán nhị phân cơ bản.
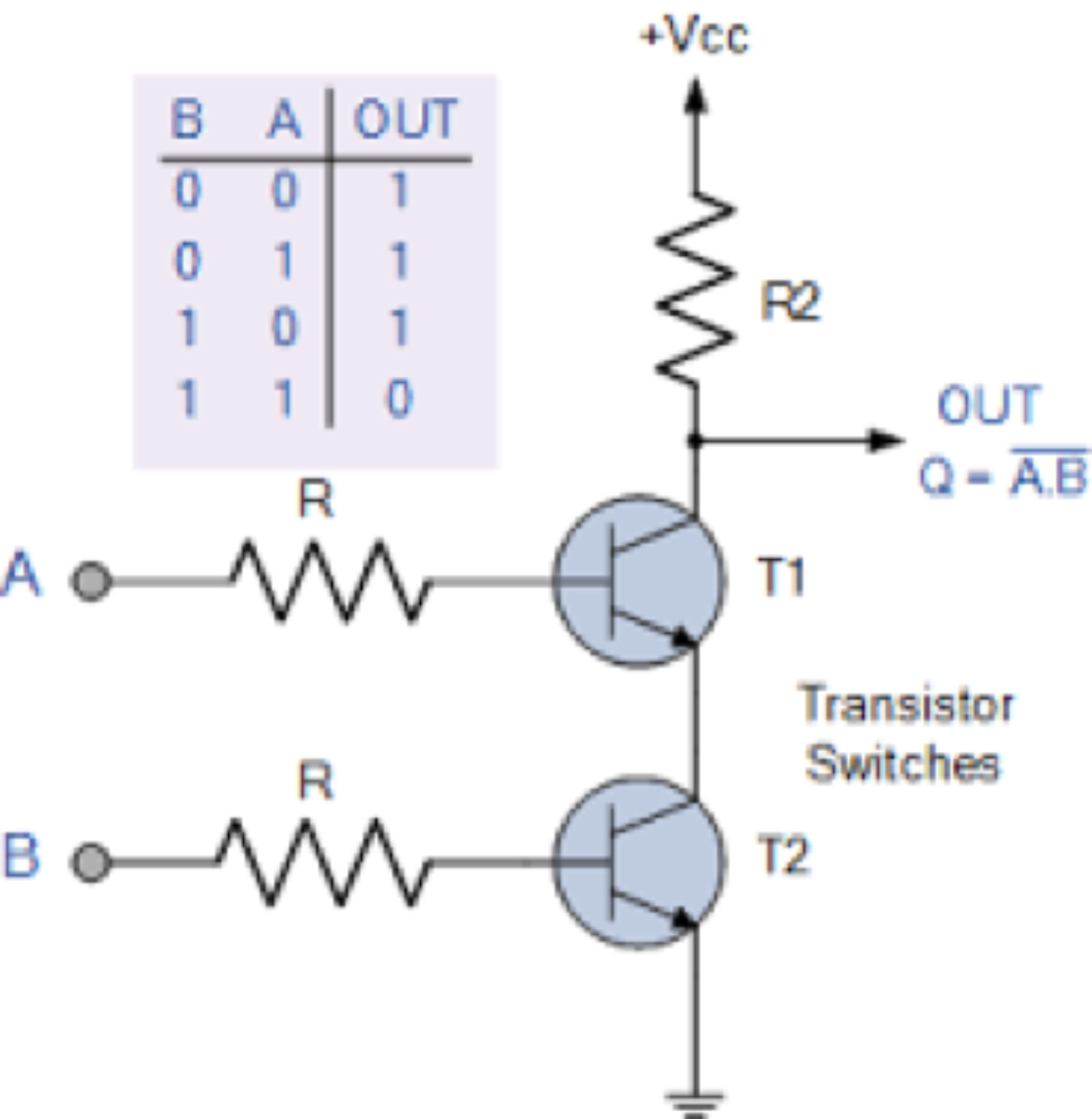
Hình 4: Cổng NAND với 2 transistor và 3 điện trở. Nguồn: https://electronics.stackexchange.com/
Với các cổng logic (AND, OR, NAND, XOR, …) chúng ta có thể tạo ra các máy tính bằng cách chuyển mọi bài toán thành dạng nhị phân, sử dụng đại số Bool, và cho các cổng logic tính toán. Sở dĩ transistor bán dẫn được chọn vì chúng có thể được sản xuất hàng loạt, giá thành rẻ, độ ổn định cao, độ bền cao. Ngày nay, người ta có thể sản xuất hàng tỷ transistor trên một chip, và hàng tỷ chip mỗi năm. Thuật ngữ số hóa được ra đời với hàm ý số 0 và 1, tương ứng với hai trạng thái đóng và mở của transistor. Và hầu như mọi hoạt động của con người hiện nay dựa trên sự đóng và mở của các transistor.
Tính toán nhị phân do vậy là một sự ngẫu nhiên lịch sử. Điện tử ra đời và phổ biến nên đã tạo ra số hóa, số hóa nhị phân. Nếu không phải điện tử thì có thể đã không có số hóa, hoặc số hóa không nhị phân.

Hình ảnh 5: Số hóa được hiểu như số nhị phân (0 và 1) và có ở trong mọi thiết bị đời sống hàng ngày.
Mặc dù vậy việc số hóa cũng có hạn chế trước hết là làm tăng số tính toán cần làm. Ví dụ như trong não bộ con người, việc cộng hai số nhỏ như 24 + 35 có thể làm trong tích tắc (giả sử đã được học cộng), thì với máy tính nó phải tuần từ số hóa các số, cộng trên nhị phân, trả lại kết quả nhị phân và tương tự hóa trở lại để hiển thị. Hơn nữa, quá trình tính toán nhị phân còn trải qua rất nhiều bước truyền dữ liệu từ thiết bị ngoại vi vào bộ nhớ, vào cache, tính toán trên ALU và trả ngược lại. Nói tóm lại, máy tính cần đến hàng ngàn chu kỳ chuyển mạch mới cộng được hai số đơn giản. (Tuy vậy nếu máy tính chạy hàng tỷ chu kỳ một giây thì nó vẫn có thể cộng hàng nghìn số trong 1 milli giây).
Quá trình tính toán nói trên như vậy rất nhân tạo và không giống các hệ tự nhiên như não bộ con người. Thực tế thì trong tự nhiên tính toán diễn ra ở rất nhiều hiện tượng mà không cần số hóa.

Hình 6: Với số hóa, để cộng hai số đơn giản máy tính có thể cần đến hàng ngàn bước

Hình ảnh 7: Một số ví dụ tính toán trong tự nhiên không số hóa: hai dòng điện cộng lại; hai sóng ánh sáng hình sin cộng lại; tuyết rơi được tích phân và sụp xuống khi đủ một ngưỡng (Hình ảnh từ Wikipedia)
Như vậy là cùng với việc tính toán nối tiếp qua ALU, việc số hóa nhị phân cũng làm tăng gánh nặng cho các bài toán AI. Hai điều này đều có từ lịch sử phát triển từ mạch điện cho đến AI.
Các hệ AI tương lai do vậy có thể được thiết kế cơ bản hơn, đi trực tiếp từ vật liệu cấu tạo thành mạng neuron, bỏ qua các transistor và quá trình số hóa và vận hành chủ yếu dựa trên các quy luật vật lý cơ bản.
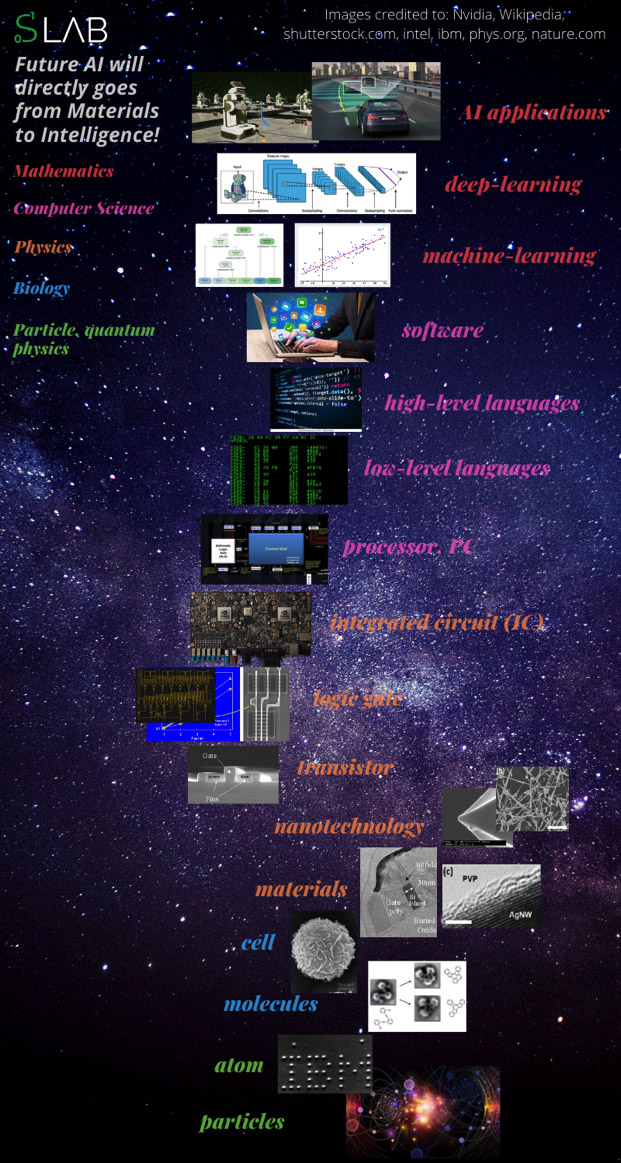
Hình 8: Các bước phát triển từ transistor đến AI và các bước thấp hơn bên dưới.
Tính toán tự nhiên hơn
Các ứng dụng AI đã tạo nên những câu chuyện thành công ngoạn mục gần đây. Hầu như tất cả mọi người đều sử dụng ít nhất một, nếu không muốn nói là nhiều ứng dụng AI trong cuộc sống hằng ngày. Mặc dù AI vẫn dựa trên máy tính của kiến trúc Neumann như đã nói ở phần 1 thì lợi nhuận AI mang lại vẫn cao hơn chi phí tính toán của nó. AI đã tạo ra sự hấp dẫn do lần đầu tiên máy tính thực sự có khả năng bắt chước các giác quan của con người, đặc biệt là thị giác và thính giác. Máy tính ngày nay có thể “nhìn”, nhận biết và phản hồi, cũng như “nghe”, hiểu và trả lời.
Tuy nhiên khi các bài toán AI trở nên phức tạp hơn các giới hạn của cấu trúc hiện tại sẽ bộc lộ và chúng ta cần tìm kiếm một giải pháp thay thế.
Hãy nhìn lại rằng mô hình AI là sự phát triển tiếp nối của mô hình mạng nơ-ron (neural network – NN), mô hình mô phỏng lại cấu trúc của bộ não, nối tiếp bởi mô hình Deep Learning (Deep Neural network – DNN). Bằng cách sử dụng nhiều lớp, DNN có thể xử lý dữ liệu tuần tự với độ phức tạp tăng dần. Bằng việc kết hợp kỹ thuật tích chập chúng ta có thể tích hợp cường độ của các điểm lân cận trong một hình ảnh giống như mắt người nhận dạng các vùng trong ảnh. (các mô hình ANN truyền thống xử lý các pixel hình ảnh một cách độc lập).
Tuy nhiên có một sự khác biệt quan trọng là cách lan truyền thông tin giữa các nơ-ron thì DNN giống máy tính hơn là não bộ. Các nghiên cứu thần kinh học đã cho thấy thông tin được lan truyền giữa các nơ-ron theo dạng các xung ngắn hay “spike”, hoặc một chuỗi các xung. Đáng ngạc nhiên, các xung này có hình dạng tín hiệu giống nhau, đồng nhất với cường độ khoảng có biên độ 100mV và độ rộng khoảng 1 milli giây. Điều này hoàn toàn trái ngược với ANN/DNN, nơi tín hiệu có giá trị liên tục và thông tin được chứa trong chính cường độ. Chính sự quan sát này đã dẫn đến một kiến trúc mạng nơ-ron mới, mạng nơ-ron dạng xung (Spiking Neural Network – SNN), ở đó thông tin được chứa theo chiều thời gian.
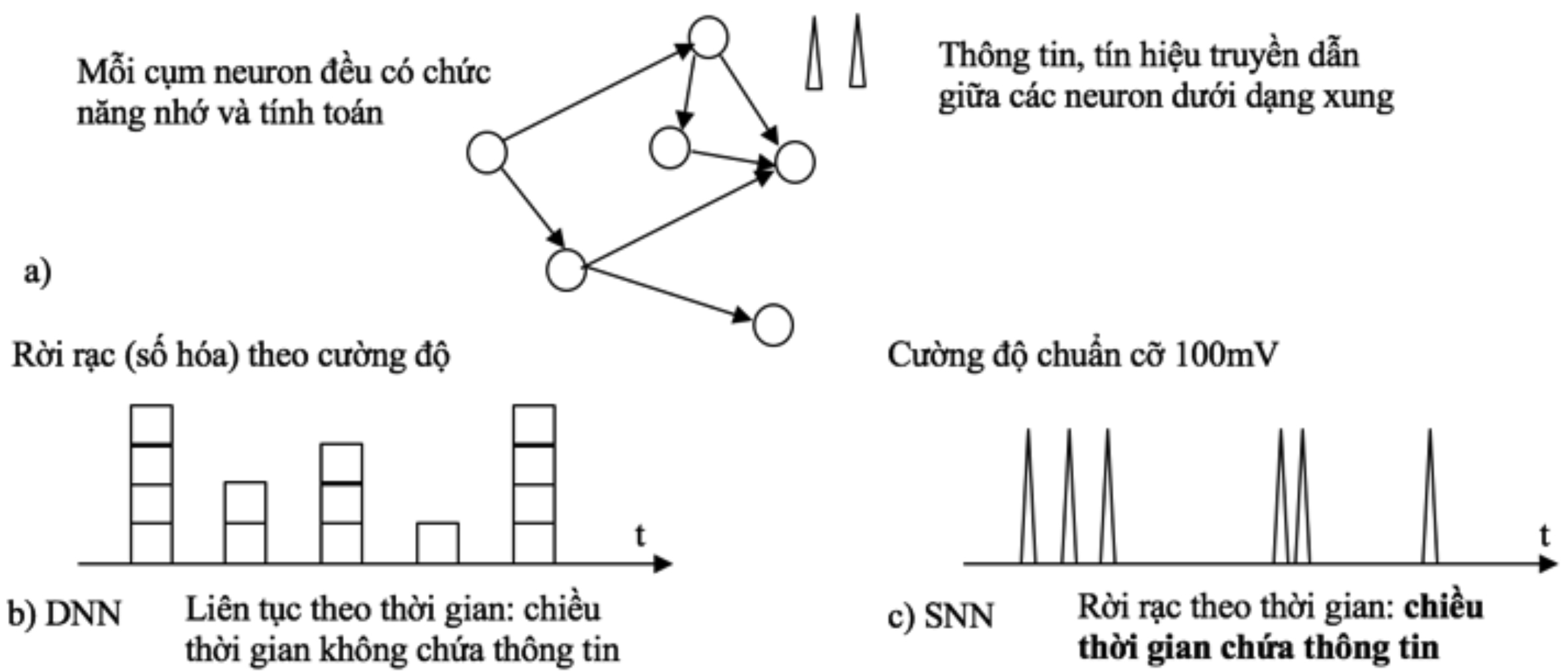
Hình 9: a) Mạng SNN: mỗi thực thể trong mạng nơ-ron thế hệ 3 gồm chức năng nhớ và tính toán. Thông tin truyền dạng xung theo thời gian. b) Mạng DNN hiện tại: Tín hiệu đồng bộ và liên tục theo thời gian, số hóa;c) Tín hiệu không đồng bộ và rời rạc theo thời gian, ở dạng xung chuẩn. Thời gian giữa xung chứa thông tin.
Hơn nữa trong SNN, thời gian giữa các xung hoặc giữa xung đến và đi khỏi dây thần kinh đã chứa toàn bộ dữ liệu nên việc xử lý thông tin được thực hiện qua xung và cấu trúc mạng SNN gần như là không đổi. Ngược lại trong DNN, người ta phải thiết kế mạng phù hợp cho từng vấn đề nhận dạng, như mạng CNN, RNN, LSTM,…
Tính phổ quát của mạng SNN có thể thấy với não bộ của chúng ta. Khi một người không may bị hỏng một giác quan (ví dụ mắt), phần não bộ xử lý thông tin của giác quan đó không còn hoạt động nữa nhưng có thể chuyển sang để xử lý thông tin từ giác quan khác (ví dụ tai), khiến cho người này nhạy bén hơn ở giác quan còn lại.
Ngoài ra vì các xung được mã hóa theo sự kiện, chúng chỉ được tạo khi dữ liệu thay đổi, ví dụ như hình ảnh có nhiều tương phản, âm thanh xuất hiện, tần các xung ít hơn nhiều so với việc mã hóa toàn bộ tín hiệu. Điều đó làm giảm đáng kể số lượng xung được tạo ra, số lượng tính toán cần thực hiện và tối ưu hóa mức tiêu thụ năng lượng. Chúng ta thấy rõ điều này khi tập trung thực hiện một nhiệm vụ, ví dụ một anh bảo vệ đang trông cửa hàng. Nếu không có khách (tín hiệu không thay đổi nhiều) thì anh ta có thể nghỉ ngơi, thậm chí thiu thiu ngủ (não hoạt động ít) mà vẫn trông được cửa hàng. Nhưng nếu có khách tới (tín hiệu biến đổi), não sẽ tạo ra xung và xử lý giúp người bảo vệ bật dậy giữ xe. Ngược lại với hệ thống giám sát AI hiện tại, máy tính chạy liên tục cả khi có và không có khách. (ngay cả khi không có khách, hình ảnh vẫn cần được xử lý để nhận dạng ra là không có khách).
Bên cạnh việc tối ưu năng lượng tiêu thụ, SNN sẽ rất phù hợp với các ứng dụng AI xử lý các tín hiệu biến đổi theo thời gian như phát hiện cử chỉ, nhắm mục tiêu di động, xe tự lái,…
Nhưng bên cạnh thông tin dạng xung thì một mạng SNN cần những gì?
Hai thành phần cơ bản khác trong mạng SNN là các nơ-ron thần kinh và các khớp thần kinh liên kết nơ-ron với nhau. Trong đó, các nơ-ron có thể mô phỏng theo cơ chế tích lũy và phát (Integrated and Fire – I&F) đơn giản như sau: nơ-ron nhận xung từ các nơ-ron khác qua các dây thần kinh làm tăng điện thế lên, đến khi điện thế vượt quá một ngưỡng xác định nơ-ron sẽ phát ra một xung và điện thế được đặt lại bằng không. Với các khớp thần kinh, các nhà khoa học thần kinh đã phát hiện ra độ dẫn điện của chúng có thể được thay đổi tùy theo hiệu số thời gian xung đến và đi. Nếu tế bào thần kinh đến kích hoạt xung trước tế bào thần kinh sau thì độ dẫn điện của khớp thần kinh sẽ tăng lên ngược lại.
Cơ chế này cho phép các khớp thần kinh “học” (điều chỉnh độ dẫn) thông qua các xung chảy qua nó và gọi là cơ chế đàn hồi xung thời gian (Spike-timing Dependent Plasticity – STDP). I&F và STDP là hai tính năng cơ bản nhất của một mạng SNN, đều lấy ý tưởng từ các cơ quan sinh học và do vậy được kỳ vọng sẽ khiến cho SNN có được hiệu suất gần hơn với trí thông minh tự nhiên.
Bên cạnh các cơ chế I & F và STDP, chúng ta cần thêm các quy tắc học cho SNN cho các bài toán AI, cả không giám sát và giám sát. Các công trình gần đây đã cho thấy sự tiến bộ về các thuật toán và quy tắc này. Vấn đề còn khó khăn hơn ở mức độ chế tạo. Ở mức cao, chúng ta có thể sử dụng máy tính kiến trúc Neumann và công nghệ CMOS để mô phỏng SNN, ví dụ:
1. SpiNNaker (Đại học Manchester) sử dụng lõi ARM9 để làm nơ-ron thần kinh, giao tiếp với nhau qua xung với giao thức hướng sự kiện. Hệ thống lớn nhất bao gồm 1 triệu lõi / bộ xử lý và mô phỏng được các chức năng cơ bản của bộ não
2. TrueNorth (IBM): nơ-ron thần kinh được tích hợp trên chip và dây thần kinh được mô phỏng bởi bộ nhớ SRAM cục bộ với một mức độ rời rạc nhất định. Các nơ-ron có thể thực hiện cơ chế I & F động và hoạt động không đồng bộ. Việc tích hợp trên chip cho ra hiệu suất năng lượng cao hơn khoảng ba cấp so với CPU thông thường.
3. Loihi (Intel): sử dụng kiến trúc sư tương tự như TrueNorth với bóng bán dẫn hiệu ứng trường kích thước 14nm. Chip chứa đựng 130.000 nơ-ron và 130 triệu khớp thần kinh, cho phép một số dạng quy tắc học tập STDP
Tuy nhiên các cấu trúc trên vẫn dựa trên công nghệ CMOS và cần số số lượng lớn mạch, transistor để mô phỏng nơ-ron và khớp nối thần kinh. Chúng đã thực hiện được các chức năng chính của SNN là I & F, STDP, giao tiếp không đồng bộ nhưng còn phức tạp về mặt kiến trúc vật liệu. Gần đây, các thiết bị trở nhớ – memristive đã nổi lên như là công nghệ nano thay thế cho công nghệ CMOS cho mạng SNN.
Đây là một điện trở với hai đầu cuối, đặc biệt ở chỗ điện trở có thể thay đổi liên tục bằng cách áp dụng các xung điện thích hợp. Tính nhớ được này được thực hiện thông qua các cơ chế vật lý khác nhau như chuyển pha, khuếch tán ion, hiệu ứng spintronic,… và có thể được sử dụng để biểu diễn các cơ chế I & F, STDP chỉ trên một linh kiện duy nhất (hoặc thêm một trở nữa). Thiết bị này trở nên đặc biệt phù hợp để triển khai SNN vì nó cho phép tích hợp rất nhiều trở nhớ, giống như cách mạch IC tích hợp transistor, tạo thành mạng SNN với hàng trăm triệu nơ-ron và khớp thần kinh. Hiệu suất như vậy cao hơn ít nhất một nghìn lần so với công nghệ hiện tại và rất thuận tiện cho việc tính toán AI (đào tạo) hay các trung tâm dữ liệu để giảm chi phí thực hiện các tính toán AI trên đám mây.
Hơn nữa, nhờ việc chỉ có hai đầu cuối, các memristor có thể được chế tạo ở dưới kích thước 10 nano mét và chuyển đổi với thời gian nano giây, cho phép tích hợp phần cứng dày hơn. Các công nghệ hiện tại vẫn đang gặp khó khăn ở việc chế tạo ổn định (các đặc tính I&F, STDP) và tích hợp quy mô lớn, nhưng memristor đang là một ứng cử viên lý tưởng cho các thiết bị AI trong tương lai. Đặc biệt phù hợp hơn cho các thiết bị nhúng cần hạn chế về năng lượng tỏa ra ví dụ: điện thoại di động, robot di động và thiết bị bay không, thiết bị internet (vạn vật),…
Tóm lại, tương lai của AI được dự đoán sẽ dựa trên công nghệ mới không bị ràng buộc bởi kiến trúc máy tính Neumann hiện tại, với các tính năng cơ bản sau:
– Tính toán quy mô lớn trên linh kiện và bộ nhớ cục bộ
– Không sử dụng (hoặc rất ít) số hóa nhị phân
– Tính toán tự nhiên hơn: dựa trên hiệu ứng vật lý/sinh học.
Trên thị trường, trở nhớ đã được dùng để chế tạo bộ nhớ (ReRAM) và đã được thương mại hóa bởi HP, Fujitsu S bán dẫn, Hynix, …. Chip AI dựa trên trở nhớ cũng đang được nghiên cứu và phát triển tích cực bởi các nhóm ở IBM, Đại học Massachusetts, với độ chính xác đang tiếp cận với kiến trúc DNN hiện tại (nhưng điện năng tiêu thụ nhỏ hơn nhiều).
Cuối cùng nhưng không kém phần quan trọng là chip AI có thể sử dụng các hiệu ứng và vật liệu khác, phi điện tử, không nhất thiết theo kiến trúc SNN nói trên. Ví dụ như Lightelligence, Luminous and Lightmatter là các start-up AI sử dụng ánh sáng để chứa thông tin và tính toán bằng các thiết bị quang học như giao thoa kế, bộ suy hao. Những start-up này được tài trợ bởi các nhà đầu tư nổi tiếng bao gồm Bill Gates và Travis Kalanick. Ngoài ra thì AnotherBrain còn đề xuất một ý tưởng táo bạo hơn là dùng các cấu trúc tế bào sinh học để thực hiện tính toán AI. AnotherBrain cũng đã được đầu tư nhiều chục triệu đô la.
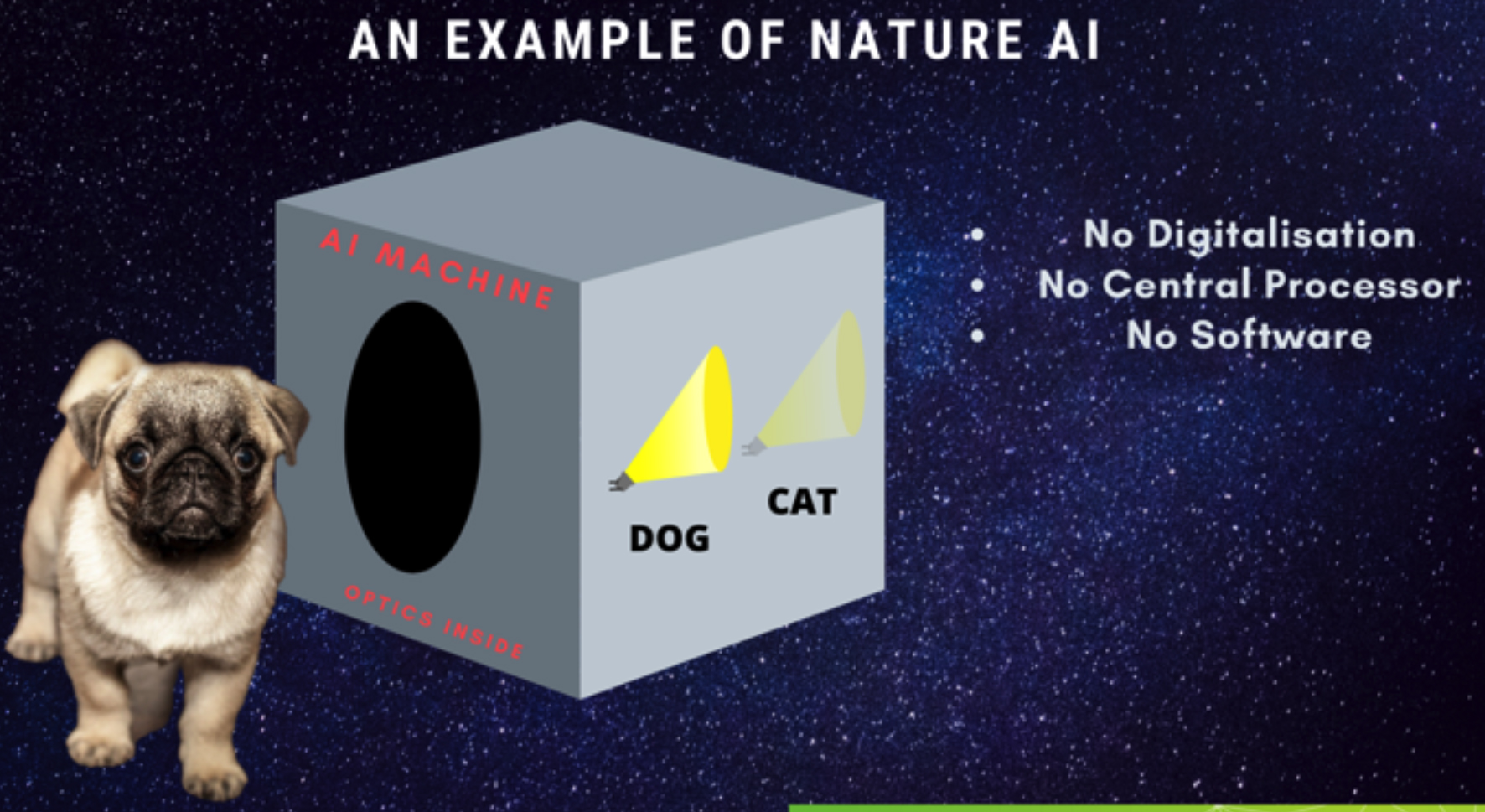
Hãy tưởng tượng trong tương lai, thiết bị AI sẽ như là một chiếc hộp đen có thể phát hiện nếu một con vật đi qua, với bên trong hoặc là các gương, giao thoa kế, … hoặc là các mạch điện nối qua các linh kiện nano. Các thiết bị này nhận dạng tức thời do truyền ánh sáng hoặc điện thế với tốc độ ánh sáng, không tính toán số, không vi xử lý và không phần mềm (hoặc rất ít để hỗ trợ). □
——-
Tài liệu tham khảo
*TS Nguyễn Quang (ĐH Quốc tế Hồng Bàng)