DNA tuổi 60: Nhìn lại thập kỷ dữ liệu lớn
Ngày 28/2/1953, cấu trúc xoắn kép (double helix) của DNA được báo cáo trong bài báo dài vỏn vẹn một trang đăng trên tạp chí khoa học Nature (Anh) bởi hai nhà khoa học người Mỹ James Watson và người Anh Francis Crick tại ĐH Cambridge. Bài báo, một trong những phát hiện khoa học vĩ đại nhất thế kỷ trước, đánh dấu bước tiến lớn cho ngành khoa học sự sống (life sciences).
2003 – Hoàn thành bản đồ gene người
Mặc dù được công bố vào năm 2001, nhưng thực sự đến năm 2003, hơn ba tỷ ký tự của bộ gene người mới hoàn toàn được công bố. Gần như ngay lập tức, các nhà khoa học đã tiến hành bước tiếp theo bằng dự án ENCODE (Encyclopedia of DNA Elements) với mục tiêu giải mã ý nghĩa các thành phần của ba tỷ ký tự bộ gene người, nỗ lực này được tài trợ bởi Viện Quốc gia về Nghiên cứu gene người (NHGRI) của Mỹ.
2004 – Công nghệ chip dữ liệu thể hiện gene ứng dụng trong y học
Công ty công nghệ sinh y học hàng đầu thế giới Roche được Cơ quan quản lý thực phẩm và dược phẩm Mỹ (FDA) thông qua ứng dụng y học đầu tiên sử dụng công nghệ chip dữ liệu thể hiện gene (microarray) chỉ chưa đầy một năm sau công bố báo chí của họ. Công nghệ microarray cho phép chúng ta đo đạc độ thể hiện (expression) của gene trong hơn 20 nghìn gene trong toàn bộ bộ gene con người, từ đó xác định được các gene có trong người của một loại bệnh cụ thể. Mặc dù hiện nay công nghệ mới chính xác và triển vọng hơn, nhưng microarray vẫn được dùng rộng rãi trong nghiên cứu y học bởi tính ưu việt về giá cả và nền tảng chuẩn hoá và ổn định trong phân tích thống kê.
2005 – Công nghệ giải mã trình tự bộ gene thế hệ mới (Next Generation Sequencing1)
Công ty công nghệ sinh học 454 Life Sciences (về sau được Roche mua lại) lần đầu tiên công bố công nghệ giải mã bộ gene thế hệ mới (tên là pryosequencing) giúp giảm đáng kể chi phí và thời gian để giải mã toàn bộ bộ gene người so với phương pháp truyền thống. Dự án bản đồ gene người bắt đầu năm 1990, công bố kết quả năm 2001, tốn hơn 3 tỷ USD; tại thời điểm đó, công nghệ cải tiến đẩy giá giải mã bộ gene còn 100 triệu, nhưng đến năm 2005 chi phí giải mã trình tự bộ gene giảm xuống hơn 10 lần, chỉ còn khoảng dưới 10 triệu USD (hình dưới), và còn giảm nữa trong những năm tiếp theo.
Cũng trong năm này, bản đồ haplotype2 đầu tiên của bộ gene người được công bố trên tạp chí Nature. Công trình là nỗ lực hợp tác quốc tế của các tổ chức nghiên cứu danh tiếng đứng đầu bởi Mỹ, Anh, Nhật, Trung Quốc, với thành công trong việc xác định hơn một triệu ký tự DNA khác nhau đại diện cho bộ gene người (mỗi người chúng ta có bộ gene của hơn ba tỷ ký tự nhưng tới xấp xỉ hơn 99% là giống nhau, nỗ lực xác định hơn một triệu SNP (Single Nucleotide Polymorphism) tạo cơ sở cho rất nhiều phát hiện thành công về nguyên nhân các loại bệnh phổ biến cũng như hiếm trên thế giới.
Vẫn năm 2005 đánh dấu sự thành công đầu tiên của phương pháp GWAS (Genome-Wide Association Studies) với mục đích tìm ra những SNP đại diện cho những loại bệnh tật trên tập dữ liệu của nhiều bệnh nhân có cùng loại bệnh khi so sánh với những người khoẻ mạnh. Công trình được công bố trên tạp chí khoa học Science của Mỹ, là tiền đề cho rất nhiều nghiên cứu GWAS sau này.
Sự kiện quan trọng không thể bỏ qua trong năm 2005 là sự ra đời của nỗ lực giải mã bộ gene của bệnh ung thư của Viện Ung thư Quốc gia Mỹ, với cái tên: The Cancer Genome Atlas, viết tắt là TCGA (bốn ký tự DNA cũng là Thymine, Cytosine, Guanine, Adenine).
2006 – Công nghệ giải mã trình tự bộ gene người tiếp tục được cải tiến
Bản đồ gene người được sử dụng với mục đích tham chiếu cho các nghiên cứu bộ gene người tiếp tục được cải thiện chính xác hơn so với bản công bố năm 2001 và 2003. Cùng thời gian này, công nghệ giải mã bộ gene mới (SBS: Sequence by Synthesis) được Công ty Solexa, sau này là Illumina3 công bố.
Năm 2006 cũng đánh dấu sự thành công trong việc lần đầu tiên xác định biến dị (mutation) trong ung thư được phát hiện trong các gene ở bệnh ung thư vú (gene BRCA: http://www.cancer.gov/cancertopics/factsheet/Risk/BRCA) và ung thư ruột kết (colon).
2007 – Bộ gene cá nhân hoàn chỉnh đầu tiên được công bố
Nhà khoa học, cựu binh chiến tranh Việt Nam Craig J. Venter cùng với công ty của ông – Celera Genomics – được nhiều người công nhận đã chiến thắng tổ chức Human Genome của Chính phủ Mỹ trong nỗ lực giải mã bộ gene người (Venter và đại diện của Viện Sức khoẻ Mỹ (NIH) cùng Tổng thống Bill Clinton công bố báo chí năm 2001), trở thành cá nhân đầu tiên công bố bộ gene gồm ba tỷ ký tự trên tạp chí truy cập miễn phí PLoS Biology.
Dự án bản đồ Hapmap cũng được cập nhật với hơn 3.1 triệu SNP xác định từ bốn khu vực dân số khác nhau trên toàn thế giới. Bản đồ hapmap càng hoàn chỉnh, khám phá xác định gene bệnh tật càng chính xác hơn.
2008 – Định luật Moore trong phát triển máy tính bị “phá vỡ” bởi công nghệ giải mã bộ gene
Giá cả giải mã toàn bộ bộ gene đã giảm xuống với kỷ lục này phá vỡ kỷ lục kia, hoàn toàn “phá vỡ” định luật Moore nổi tiếng về giá cả bộ vi xử lý sẽ giảm xuống ½ sau 18 tháng. Hình dưới cho thấy giá cả giải trình tự bộ gene hoàn chỉnh giảm hơn 10 lần chỉ sau một năm (2007-2008), và hiện nay 2013 giá này xuống dưới mức 10.000 USD.
Bộ gene của Jame D. Watson, người đồng khám phá cấu trúc double helix của bộ gene, được giải mã bởi kỹ thuật thế hệ mới.
Bộ gene bệnh nhân ung thư đầu tiên được công bố bởi các nhà khoa học ở ĐH Washington, Mỹ trên tập san Nature.
Công ty Knome công bố giá 350.000 USD cho việc giải trình tự bộ gene người thương mại hoá đầu tiên. Cũng từ đây, thuật ngữ “Pesonalized Genome” được sử dụng nhiều hơn, với ước mơ thay vì bệnh án, điện đồ, các bác sĩ sẽ xem các thay đổi trong bộ gene con người so với lần khám bệnh trước.
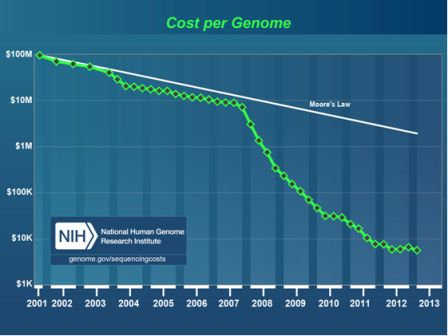
Nguồn: genome.gov
2009 – Dự án giải mã 10.000 bộ gene
Giải mã bộ gene của 10.000 sinh vật có xương sống (vetebrates) nhằm xây dựng cơ sở dữ liệu phục vụ cho những nghiên cứu quan trọng trong tiến hoá của các loài vật trên trái đất được khởi động.
Giải mã epi-genetic4 người đầu tiên, công trình đứng thứ hai trong 10 khám phá khoa học vĩ đại nhất của năm (cùng với công trình Bổ đề cơ bản của GS Ngô Bảo Châu, đứng thứ 7) do tạp chí Time bình chọn. Các tác giả đến từ Viện nghiên cứu Salk ở San Diego, California, Mỹ đạt được một bước tiến quan trọng trong khám phá hoạt động và chức năng của bộ gene người bằng việc công bố bản đồ epigenome5 của tế bào da và tế bào gốc.
2010 – Công bố bộ gene người cổ đại
Svante Paboo ở Viện nghiên cứu Max Planc ở TP Leipzig của Đức công bố bộ gene của người cổ đại trên tạp chí Science. Công trình chỉ ra mối liên hệ giữa người cổ và người hiện đại thông qua một tập hợp các gene chung (tới 99.7% là giống nhau – so với con số 98% của người và loài vượn người (chimpanzee) công bố năm 2007, sau này tính toán lại là 94%). Nỗ lực tuyệt vời này giúp loài người chúng ta hiểu sâu thêm về nguồn gốc tiến hoá của mình.
Dự án ModENCODE công bố giải mã bộ gene của hai loài sinh vật mẫu tiêu biểu là C.Elegans và Drosophila (ruồi giấm) song song với thành công của dự án ENCODE.
2011 – Công bố GWAS thứ 1.000
GWAS tiếp tục thành công với công trình khoa học thứ 1.000. Ngày càng nhiều SNP liên quan đến các loại bệnh tật phổ biến và nghiêm trọng được phát hiện ra giúp thúc đẩy nhiều tiến bộ trong nâng cao kiến thúc trị bệnh của loài người.
Dự án i5K được khởi công với nỗ lực giải mã 5.000 loài côn trùng (arthropod species) nhằm tìm hiểu cơ chế sinh học phân tử của đa dạng sinh học phục vụ cho lợi ích trong nông nghiệp và khoa học. Dự án này và nhiều dự án khác chứng tỏ sức mạnh của công nghệ sinh học và công nghệ tính toán, đẩy nhanh những tiến bộ y sinh học của nhân loại trong nỗ lực cải thiện chất lượng cuộc sống, đẩy lùi bệnh tật.
2012 – ENCODE công bố dữ liệu
ENCODE công bố hơn 30 bài báo trên các tạp chí khoa học hàng đầu như Nature, Genome Research, cùng với 15 terabytes dữ liệu hoàn toàn miễn phí cho bạn đọc. Một trong những thông tin hấp dẫn nhất dự án này công bố là việc hơn 80% của hơn ba tỷ ký tự bộ gene người đều có chức năng sinh hoá (biochemically active) và hầu hết đều có chức năng sao mã (transcribed) thành mRNA rồi thành protein, đơn vị quy định hình thái (phenotype) của cơ thể con người. Đây là một tin bất ngờ cho khoa học bởi khi dự án giải mã bộ gene người được công bố, người ta luôn tin là phần lớn bộ gene là “junk” (không có tác dụng gì cả trong việc mã hoá protein). Con số hơn 80% của ENCODE hiện nay cũng khá gây tranh cãi trong giới khoa học.
Dự án 1.000 bộ gene người công bố trên Nature với sự đa dạng về địa lý và sinh học cuả 1.092 người đến từ bốn vùng dân cư khác nhau trên thế giới, bao gồm cả bản đồ khá hoàn thiện của 38 triệu SNPs (nhiều hơn 10 lần so với công bố năm 2007).
Cũng trong năm ngoái, Công ty CompleteGenomics công bố thương mại hoá việc giải mã bộ gene người với chỉ 5.000 USD. Sở hữu cá nhân bản đồ bộ gene người ngày càng trở nên hiện thực hơn bao giờ hết.
2013 – Kỷ nguyên khai phá dữ liệu sinh y học – thay cho lời kết6
Chúng ta đang đứng trước một thời đại tuyệt vời của khám phá sinh học, chi phí giải mã bộ gene đã giảm đến mức các dự án cấp quốc gia và cấp Bộ ở Việt Nam đều có thể chi trả. Ngay cả trong trường hợp chưa thể tạo ra dữ liệu, cơ hội khám phá vẫn còn rất hứa hẹn cho khoa học Việt Nam vốn có truyền thống mạnh về giải thuật tính toán, bởi các trung tâm sản xuất dữ liệu lớn đều phải công bố dữ liệu trong một thời gian nhất định (6-12 tháng) theo quy định của các tổ chức tài trợ khoa học trên thế giới. Với kiến thức khoa học máy tính và thống kê, các nhóm nghiên cứu ở Việt Nam hoàn toàn có thể tham gia vào bức tranh vô cùng sống động trong khám phá khoa học sự sống tính và có thể có những thành tựu đáng kể trong thập kỷ tới nếu Nhà nước có những đầu tư trọng điểm, đúng đắn, thu hút được người Việt tài năng ở trong và ngoài nước trong một lĩnh vực yêu cầu sự hợp tác liên ngành tiêu biểu. Đây cũng là cơ hội cho sự phát triển công nghệ sinh học nước nhà, khi các chi phí giải mã bộ gene người không còn là trở ngại đáng kể (10,000 USD tương đương hơn 200 triệu đồng Việt Nam, chưa bằng một phần nhỏ tiền thưởng một trận thắng đá bóng của các ông bầu Việt Nam thời chịu chơi).
Nguồn: http://www.the-scientist.com/images/May2013/TS-DNA_Poster-web1.jpg
—
* Đại học Nam California, Mỹ
1 Thuật ngữ tạm dịch, mong bạn đọc chỉnh sửa nếu thiếu chính xác
2 Haplotype là một khái niệm trong sinh học chỉ tập hợp các SNP trên một nhiễm sắc thể – sự khác nhau ở từng ký tự DNA của các bộ gene khác nhau hoặc các cặp nhiễm sắc thể khác nhau. Haplotype map (gọi tắt là HapMap) là bản đồ tổng hợp các mẫu chung của dự đa dạng di truyền của loài người.Bản đồ này có ý nghĩa quan trọng trong nghiên cứu tiến hoá và y học.
3 Công ty công nghệ sinh học có trụ sở ở San Diego, California, Mỹ, với công nghệ giải mã được ưa dùng nhất hiện nay.
4 Một bộ môn khoa học nghiên cứu về tương tác giữa gene và môi trường ở cấp độ phân tử và tế bào, theo http://nguyenvantuan.net/health/2-health/1568-bai-hoc-lam-khoa-hoc-co-dao-duc-giai-nobel-y-sinh-2012
5 Bộ gene người chỉ có một, nhưng epi-genome (epi – thuật ngữ tiếng Hy Lạp nghĩa là ở trên) thì có rất nhiều – xuất phát từ những thay đổi sinh hoá của DNA và protein tên là histone, chúng đóng vai trò quan trọng trong điều hoà gene (gene regulation).
6 Đoạn kết thể hiện quan điểm cá nhân của tác giả.