Nửa thế kỷ trí tuệ nhân tạo
Trí tuệ nhân tạo là một lĩnh vực của khoa học và công nghệ nhằm làm cho máy có những khả năng của trí tuệ và trí thông minh của con người, tiêu biểu như biết suy nghĩ và lập luận để giải quyết vấn đề, biết giao tiếp do hiểu ngôn ngữ và tiếng nói, biết học và tự thích nghi, … Hơn nửa thế kỷ qua, cùng với rất nhiều những thành tựu, ngành TTNT cũng có không ít những dự đoán không thành.
Mong muốn làm cho máy có những khả năng của trí thông minh con người đã có từ nhiều thế kỷ trước, tuy nhiên TTNT chỉ xuất hiện khi con người sáng tạo ra máy tính điện tử (MTĐT). Alan Turing−nhà toán học lỗi lạc người Anh, người được xem là cha đẻ của Tin học do đưa ra cách hình thức hóa các khái niệm thuật toán và tính toán trên máy Turing−một mô hình máy tính trừu tượng mô tả bản chất việc xử lý các ký hiệu hình thức−có một đóng góp quan trọng và thú vị cho TTNT vào năm 1950, gọi là phép thử Turing.
Phép thử Turing là một cách để trả lời câu hỏi ‘máy tính có biết nghĩ không?’, được phát biểu dưới dạng một trò chơi. Hình dung có ba người tham gia trò chơi, một người đàn ông (A), một người đàn bà (B) và một người chơi (C). Người chơi ngồi ở một phòng tách biệt với A và B, không biết gì về A và B (như hai đối tượng ẩn X và Y) và chỉ đặt các câu hỏi cũng như nhận trả lời từ A và B qua một màn hình máy tính. Người chơi cần kết luận trong X và Y ai là đàn ông ai là đàn bà. Trong phép thử này, A luôn tìm cách làm cho C bị nhầm lẫn và B luôn tìm cách giúp C tìm được câu trả lời đúng. Phép thử Turing thay A bằng một máy tính, và bài toán trở thành liệu C có thể phân biệt được trong X và Y đâu là máy tính đâu là người đàn bà. Phép thử Turing cho rằng máy tính là thông minh (qua được phép thử) nếu như biết cách làm sao cho C không thể chắc chắn kết luận của mình là đúng. Tuy phép thử Turing đến nay vẫn được xem có tầm quan trọng lịch sử và triết học hơn là giá trị thực tế (vì con người vẫn chưa làm được máy hiểu ngôn ngữ và biết lập luận như vậy), ý nghĩa rất lớn của nó nằm ở chỗ đã nhấn mạnh rằng khả năng giao tiếp thành công của máy với con người trong một cuộc đối thoại tự do và không hạn chế là một biểu hiện chính yếu của trí thông minh nhân tạo.
 |
Trăn trở về những chiếc máy tính thông minh đã thôi thúc nhiều nhà khoa học trong nhiều năm tiếp theo, để rồi TTNT−với tư cách là một khoa học độc lập−đã ra đời chỉ chừng 10 năm sau khi những chiếc máy tính đầu tiên được tạo ra để dùng chính vào việc tính toán (thực hiện các phép tính số học cộng trừ nhân chia và so sánh bằng nhau khác nhau).
Người ta vẫn lấy hội nghị mùa hè năm 1956 tại trường Dartmouth ở Mỹ làm sự kiện ra đời của ngành TTNT. Hội nghị đầu tiên này do Marvin Minsky và John McCarthy tổ chức với sự tham dự của vài chục nhà khoa học, trong đó có Allen Newell và Herbert Simon. Bốn người này luôn được coi là những người sáng lập của ngành TTNT. Nhiều người tham gia hội nghị Dartmouth sau này đã trở thành những thủ lĩnh về nghiên cứu TTNT trong nhiều thập kỷ, trong đó có giáo sư Donald Michie, một người tiên phong về TTNT ở châu Âu, người đã lập ra phòng thí nghiệm TTNT nổi tiếng tại đại học Edinburgh ở Anh. Chính tại hội nghị Dartmouth, McCarthy đã đề nghị tên gọi ‘artificial intelligence’. Mặc dù còn tranh cãi trong một thời gian, tên này vẫn được thừa nhận và dùng cho đến nay.
Ba trong bốn người sáng lập ngành TTNT đều ở tuổi 29 vào mùa hè 1956 tại Dartmouth (trừ Herbert Simon, người nhận giải Nobel năm 1978 về những đóng góp trong nghiên cứu về quá trình trợ giúp quyết định trong kinh tế, năm đó 40). Những người sáng lập ngành TTNT đều lần lượt được nhận giải Turing của ACM (Hội Tin học lớn nhất thế giới)−được xem là giải Nobel của Tin học, mỗi năm thường chỉ trao cho một người: Minsky (1969), McCarthy (1971), Newell và Simon (1975). Tính đột phá của tuổi trẻ và tài năng đã thôi thúc họ nghĩ đến, đặt ra và đi tìm lời giải cho những vấn đề nền tảng của TTNT, như đề xuất Dartmouth cho những người làm nghiên cứu về TTNT: “mọi khía cạnh của khả năng học tập cũng như mọi tính chất khác của trí thông minh đều có thể mô tả được thật chính xác sao cho có thể làm ra máy để thực hiện chúng”, hoặc giả thuyết của Newell và Simon tiên đoán bản chất của trí thông minh là việc điều khiển ký hiệu: “mọi hệ ký hiệu hình thức đều có các cách cần và đủ để thực hiện các hành động thông minh phổ quát”.
 |
Một chuyện được quan tâm nữa là liệu máy có mô phỏng được bộ não con người? Một số người khi này đã quả quyết rằng về mặt công nghệ hoàn toàn có thể sao chép y chang bộ não người vào phần cứng và phần mềm máy tính, và do vậy bộ não mô phỏng trong máy tính hầu như hoàn toàn giống bộ não thật. Nhiều hệ lập luận tổng quát hay các hệ hiểu ngôn ngữ con người (thường được gọi là ‘ngôn ngữ tự nhiên’) như ELIZA hay SHRDLU (tên này được ghép từ sáu chữ cái xuất hiện nhiều nhất trong tiếng Anh) được phát triển trong thời gian này. Rất lạc quan, năm 1965 Simon tuyên bố: “Máy móc trong vòng hai mươi năm nữa sẽ có khả năng làm tất cả mọi việc con người làm”, hoặc năm 1967 Minsky tiên đoán: “Quãng một thế hệ nữa, việc tạo ra trí thông minh nhân tạo sẽ cơ bản được giải quyết”.
Tuy nhiên nhiều mong đợi đã không đến. Những tiên đoán này và nhiều tiên đoán khác đã không thành sự thật. Các hệ thông minh vạn năng dựa trên lập luận hình thức đã không thành công. Sau hơn một thập kỷ của những hứng khởi và lãng mạn, thập kỷ 70 của thế kỷ trước là những năm thiên hạ thất vọng tràn trề về TTNT. Chính phủ Mỹ và Anh đã cắt bỏ nhiều đề tài nghiên cứu trong lĩnh vực này.
 |
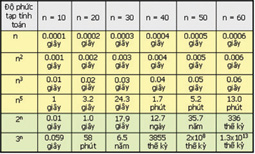
Nhưng những thất bại ở giai đoạn này cũng giúp giới nghiên cứu hiểu rõ hơn những hạn chế tính toán của các hệ lôgích hình thức, hạn chế về những gì máy có thể làm được như đã chỉ ra bởi định lý Gödel về tính không đầy đủ, phát biểu năm 1931, rằng với mọi hệ hình thức đều có những mệnh đề đúng không thể chứng minh được. Con người cũng hiểu rõ hơn khả năng tính toán bằng máy phụ thuộc rất nhiều vào độ phức tạp tính toán của từng bài toán. Rất nhiều bí ẩn vẫn thách thức ở phía trước. Câu hỏi ‘P = NP?’ về độ phức tạp tính toán do Stephen Cook đặt ra năm 1971 đã trở thành một trong bảy bài toán thách đố của thế kỷ 21 do Viện Toán Clay công bố ngày 24.5.2000. (Nói nôm na, P là tập hợp các bài toán có thể giải trên máy với thời gian là một hàm đa thức của kích thước dữ liệu, còn NP là tập hợp con của tập non-P các bài toán được dự đoán là chỉ giải được với thời gian hàm mũ của kích thước dữ liệu, nhưng có đặc điểm là ta có thể kiểm chứng trong thời gian đa thức xem các nghiệm dự đoán của mỗi bài toán trong NP có thật sự là nghiệm hay không.) Rất nhiều vấn đề của TTNT liên quan đến bài toán này.
Những năm đầu thập kỷ 80 của thế kỷ trước đã chứng kiến sự bắt đầu của một giai đoạn quãng 15 năm của sự hồi sinh, bùng nổ và thi đua quốc tế trong ngành TTNT. Ý tưởng cơ bản để phát triển TTNT khi này là sự thông minh của máy tính không thể chỉ dựa trên việc suy diễn lôgích mà phải dựa cả vào tri thức con người, và dùng khả năng suy diễn của máy để khai thác các tri thức này. Cốt lõi của TTNT có thể diễn giải bởi công thức
TTNT = Tri thức + Suy diễn
 |
 |
Thành quả và nỗ lực tiêu biểu trong giai đoạn này là sự phát triển của các hệ chuyên gia (expert systems). Mỗi hệ chuyên gia về cơ bản gồm hai thành phần: một cơ sở tri thức chứa các tri thức của chuyên gia trong một lĩnh vực và một cơ chế suy diễn logic nhằm vận dụng các hiểu biết này để giải quyết các vấn đề cụ thể, với hiệu quả như chính các chuyên gia giải quyết. Các hệ chuyên gia được nghiên cứu và xây dựng khắp nơi. Hai hệ tiêu biểu là DENDRAL và MYCIN. Hệ DENDRAL nhằm giúp các nhà nghiên cứu hóa học hữu cơ xác định các phân tử hữu cơ chưa biết dựa trên phân tích phổ của chúng và các tri thức hóa học. DENDRAL do Edward Feigenbaum−một học trò của Simon, người được coi là cha đẻ của các hệ chuyên gia và được giải Turing năm 1994−và đồng nghiệp làm tại Đại học Stanford từ cuối những năm 1960. MYCIN là hệ chuyên gia có cơ sở tri thức chừng 600 luật về y học có tính đến yếu tố bất định. Từ quãng những năm đầu của thập kỷ 90, khái niệm hệ chuyên gia được nhìn rộng hơn thành khái niệm các hệ dựa trên tri thức (knowledge-based systems) theo nghĩa cơ sở tri thức không nhất thiết cần hạn chế với tri thức chuyên gia. Ý thức được vai trò của tri thức trong các hành vi thông minh của máy, con người lại phải đối mặt với bài toán làm sao có được tri thức để máy dùng. Trở ngại này vốn luôn luôn là điểm ‘tắc’ trong sự phát triển TTNT.
 |
Quãng 15 năm này là thời phát triển sôi nổi nhiều nội dung của TTNT: về xử lý ngôn ngữ tự nhiên, như việc dịch các văn bản từ một ngôn ngữ này sang một ngôn ngữ khác; về sự thăng hoa của các phương pháp mạng neuron, vốn ra đời từ 1957 dưới dạng các perceptron đơn giản nhưng bị thờ ơ khi con người nhận ra các hạn chế của chúng; về tính toán tiến hóa, tiêu biểu là các giải thuật di truyền; về các tác tử tự trị và thông minh, những thứ có vai trò rất lớn với TTNT trong những năm về sau, …
Một chuyện đáng nhớ trong giai đoạn này là cuộc thi đua quốc tế về TTNT, khởi nguồn từ đề án máy tính thế hệ thứ 5 FGCS (Fifth Generation Computer Systems) của Nhật Bản do Bộ Ngoại thương và Công nghiệp (MITI) phát động. FGCS kéo dài trong 10 năm (1982-1992) với kinh phí ban đầu 450 triệu USD vào năm 1982. Đề án FGCS nhằm làm ra các hệ máy tính có khả năng suy diễn và giao tiếp bằng ngôn ngữ tự nhiên trên nền tính toán song song. Mặc dù cuối cùng bị đánh giá là thất bại do không đạt được các mục tiêu, đề án FGCS đã kích thích một cuộc thi đua quốc tế trong giai đoạn hồi sinh của TTNT, đặt ra và thách thức nhiều vấn đề cho giới nghiên cứu trên toàn thế giới. Nước Mỹ đã dành một kinh phí tương đương với FGCS trong các dự án TTNT của DARPA (cơ quan quản lý các đề tài nghiên cứu tiên tiến của quốc phòng). Các cường quốc khoa học ở châu Âu như Anh, Pháp, Đức cũng có những đầu tư rất lớn cho TTNT.
Từ 1956 đến nay đã là chặng đường 50 năm. Ba giai đoạn ta vừa nói trong 40 năm đầu có thể gọi tên là ‘mơ ước’, ‘thất bại’ và ‘hồi sinh’. Vậy hơn mười năm qua TTNT đã ra sao?
Không thể nói đến sự phát triển của bất cứ lĩnh vực nào trong Tin học và CNTT nếu không liên hệ với hai sự kiện ‘đổi đời’: một là sự ra đời của công nghệ vi mạch và máy vi tính vào cuối những năm 1970 và hai là sự ra đời của Internet và sự hòa nhập của CNTT và truyền thông (ICT) vào đầu những năm 1990. Trong một chừng mực nào đấy, từ hơn mười năm qua có thể mở rộng công thức cơ bản của TTNT thành
TTNT = Tri thức + Suy diễn + Môi trường
Ở đây ‘môi trường’ là Internet, là các thiết bị liên lạc không dây, là các thiết bị tính toán và lưu trữ thông tin ngày càng nhỏ hơn và mạnh hơn.
 |
 |
Có thể thấy hai đặc trưng chính của TTNT trong hơn mười năm vừa qua. Thứ nhất là từ những thành bại trong giai đoạn hồi sinh, con người đã thấy rằng TTNT vẫn chỉ ở trong buổi đầu của sự phát triển, và bài học lớn nhất của những năm 1980 là TTNT không thể phát triển một mình, mà ngược lại những khả năng của TTNT cần phải và đã được hợp tác phát triển trong các hệ thống của CNTT và các khoa học khác. Thứ hai là nhiều lĩnh vực mới của TTNT đã ra đời và tiến triển sôi động theo sự thay đổi của môi trường tính toán và tiến bộ khoa học. Chẳng hạn sự xuất hiện của những hệ dữ liệu lớn với quan hệ phức tạp như dữ liệu Web, dữ liệu sinh học, thư viện điện tử, … đã là động lực ra đời các ngành khai phá dữ liệu, Web ngữ nghĩa, tìm kiếm thông tin trên Web. Thêm nữa, TTNT đã thâm nhập từ các khoa học vi mô như góp phần giải các bài toán của sinh học phân tử (tin-sinh học) đến các khoa học vĩ mô như nghiên cứu vũ trụ, rồi cả khoa học xã hội và kinh tế như phát hiện các cộng đồng mạng trong xã hội hay phân tích các nhóm hành vi. Cũng có thể chăng gọi những năm vừa qua của TTNT là giai đoạn ‘hòa nhập’?
Trong các thành công của TTNT giai đoạn này có sự kiện máy tính thông minh tranh tài với các kỳ thủ cờ vua, và đặc biệt máy tính Deep Blue của IBM với trí tuệ nhân tạo đã đánh bại nhà vô địch cờ vua thế giới Garry Kasparov vào năm 1997, và cuối năm 2006 máy tính Deep Fritz lại đánh bại nhà vô địch Kramnik.
Một lĩnh vực tiêu biểu của TTNT trong giai đoạn này là các tác tử thông minh. Tác tử (agent), theo nghĩa chung nhất, là một thực thể có khả năng hành động để thực hiện những nhiệm vụ được giao. Một người đưa hàng, một luật sư hay một điệp viên là những tác tử. Một robot cứu người sau động đất hay một robot hút bụi trong nhà là những tác tử. Một chương trình được cài trên máy tính để lọc thư rác hay một chương trình luôn xục xạo trên Internet để tìm những thông tin mới về một chủ đề là những tác tử. Nói nôm na, tác tử thông minh là những tác tử biết hành động với các phẩm chất của trí thông minh, tiêu biểu là biết nhận thức môi trường xung quanh và biết hướng các hành động tới việc đạt mục đích. Một robot hút bụi sẽ là thông minh nếu biết tìm đến các chỗ bẩn trong phòng để hút bụi và không đi tới những chỗ đã làm.
Nhìn nhận các phương pháp và phát triển TTNT theo quan điểm tác tử thông minh đang trở nên phổ biến trong những năm vừa qua. Nhiều người tin rằng, để thành công các hệ TTNT cần phải có khả năng tự hành động và hành động linh hoạt trong một môi trường thay đổi, không dự đoán được trước, chẳng hạn như Internet (đây chính là các yêu cầu cơ bản của các tác tử thông minh).
VÀI LĨNH VỰC CỦA TRÍ TUỆ NHÂN TẠO
Có nhiều nội dung nghiên cứu và phát triển của TTNT, từ cách để máy có thể suy diễn lôgích và nhận thức, cách ra quyết định và giải quyết vấn đề, cách biểu diễn tri thức con người trong máy, cách lập kế hoạch hành động, hay cách máy biết tự học để tạo ra tri thức mới, … đến dịch tự động các ngôn ngữ, tìm kiếm thông tin trên Internet, robot thông minh. Ta nói về một vài lĩnh vực của TTNT có nhiều thay đổi trong những năm vừa qua.
Xử lý ngôn ngữ tự nhiên
Là việc làm cho máy có thể nhận biết và hiểu tiếng nói và ngôn ngữ của con người.
Liệu máy có thể nói được như người?
Đây là bài toán tổng hợp tiếng nói, tức việc làm cho máy biết đọc các văn bản thành tiếng người. Có thể hình dung nếu ta đưa cho máy các luật phát âm các âm tiết, bài toán này sẽ là việc áp dụng các luật này vào các âm tiết trong một từ để tạo ra cách đọc từ này. Đã có nhiều hệ thống tạo ra được giọng đọc tự nhiên của con người hoặc đọc giống giọng một người nào đấy, nhất là cho các ngôn ngữ được nghiên cứu nhiều như tiếng Anh. Nhưng vẫn cần rất nhiều thời gian để làm được như vậy cho các ngôn ngữ ít được nghiên cứu như tiếng Việt, hoặc làm cho máy thể hiện được buồn vui mừng giận khi nói như người.
Liệu máy có thể nhận biết được tiếng người nói?
 |
Đây là bài toán nhận dạng tiếng nói, tức việc làm cho máy biết chuyển tiếng nói của người từ microphone thành dãy các từ. Dễ thấy đây là bài toán rất khó, vì âm thanh người nói là liên tục và các âm quyện nối vào nhau, vì mỗi người mỗi giọng, vì có các âm thanh khác nhiễu vào microphone, …. Với tiếng nói chuẩn, các hệ hiện đại cũng mới nhận dạng đúng được khoảng 60-70%. Đại thể, máy mới nhận biết tốt tiếng nói của từng người riêng biệt với lượng nhỏ từ vựng và phải ‘tập nghe’ với chính giọng của người đó. Với các phương pháp học thống kê trên các kho ngữ âm tốt, ta có thể sớm hy vọng vào các hệ nhận dạng tiếng nói thông minh và chính xác.
Liệu máy có hiểu được tiếng nói và văn bản của con người?
Hiểu ngôn ngữ là một đặc trưng tiêu biểu của trí tuệ và việc làm cho máy hiểu được ngôn ngữ là một trong vài vấn đề khó nhất của TTNT nói riêng và CNTT nói chung. Ta lấy thí dụ của Marvin Minsky năm 1992 khi lý giải tại sao vấn đề này lại khó và lĩnh vực này tiến chậm: “Xét một từ, chẳng hạn ‘sợi dây’. Ngày nay không một máy tính nào có thể hiểu nghĩa từ này như con người. Ta có thể kéo một vật bằng một sợi dây, nhưng không thể đẩy một vật bằng sợi dây. Ta có thể gói một gói hàng hoặc thả diều bằng một sợi dây, nhưng không thể ăn sợi dây này. Trong vài phút, một đứa trẻ nhỏ có thể chỉ ra hàng trăm cách dùng hoặc không dùng một sợi dây, nhưng không máy tính nào có thể làm việc này”.
Để hiểu nghĩa một câu, máy không chỉ cần biết nghĩa từng từ, mà trước hết phải biết phân tích được câu này về mặt ngữ pháp. Để làm việc này, đại thể máy phải tách câu thành các từ đơn lẻ hay cụm từ, nhận biết chúng là các loại từ gì, rồi xác định cấu trúc của câu, đoán nghĩa của từng từ, và giải nghĩa cả câu. Ngôn ngữ thường nhập nhằng đa nghĩa và điều này trở nên vô cùng khó với máy. Lấy một thí dụ quen thuộc của câu đơn giản ‘ông già đi nhanh quá’. Với hai cách phân tách từ và cụm từ thành (ông già)(đi)(nhanh quá) và (ông)(già đi)(nhanh quá), với các nghĩa khác nhau của động từ ‘đi’, của cụm từ ‘ông già’,… ta cũng có dăm cách hiểu câu nói trên. Làm sao để máy tự động hiểu đúng nghĩa một câu nói bất kỳ còn là một thách thức lâu dài của ngành TTNT.
Dịch tự động
Liên quan đến hiểu ngôn ngữ là việc dịch tự động từ tiếng này sang tiếng khác, chẳng hạn dịch câu ‘ông già đi nhanh quá’ sang tiếng Anh. Việc dịch này đòi hỏi máy không những phải hiểu đúng nghĩa câu tiếng Việt mà còn phải tạo ra được câu tiếng Anh tương ứng. Nhiều dự án dịch tự động đã được theo đuổi từ hàng chục năm qua, và chắc còn phải tiếp tục nhiều chục năm nữa để có được những hệ dịch tốt. Tuy nhiên, những tiến bộ gần đây của các phương pháp dịch thống kê trên các kho ngữ liệu lớn và tốt có thể cho phép đến một ngày ai cũng nhờ máy đọc được sách báo từ hàng chục thứ tiếng.
Tìm kiếm thông tin trên mạng
Đây là lĩnh vực có sự chia sẻ nhiều nhất giữa TTNT và Internet, và ngày càng trở nên hết sức quan trọng. Sẽ sớm đến một ngày, mọi sách báo của con người được số hóa và để lên mạng hay các thư viện số cực lớn. Giả sử ta muốn tìm những tài liệu liên quan đến việc ‘trí tuệ nhân tạo đóng góp vào việc nâng cao thành tích ở thế vận hội’. Nếu dùng Google để tìm với các từ khóa tiếng Anh ‘artificial intelligence’, ‘performance’ và ‘olympic’ hay dùng một hệ nào đó như Xalộ (http://www.xalo.com.vn/) để tìm với từ khóa tiếng Việt ‘trí tuệ nhân tạo’, ‘thành tích’, ‘thế vận hội’, ta sẽ nhận được rất nhiều tài liệu không phải thứ ta muốn tìm, cũng như có nhiều tài liệu liên quan không được tìm ra.
Có ít nhất hai cách để TTNT đóng góp vào việc giải bài toán này. Một là hệ tìm kiếm cho phép đưa vào câu hỏi ở dạng ngôn ngữ tự nhiên, phân tích để hiểu nghĩa câu hỏi và có cơ chế tìm kiếm các văn bản trong thư viện theo nghĩa này. Hai là hệ tìm kiếm sẽ mô hình các từ ‘trí tuệ nhân tạo’, ‘thành tích’, và ‘thế vận hội’, mỗi mô hình là một tập hợp nhiều từ khác kèm theo phân bố xác suất của chúng theo những quy luật thống kê. Thay vì tìm kiếm trên mạng hay trong thư viện với ba từ khóa, hệ sẽ tìm kiếm với ba tập hợp từ. Với các phương pháp ‘thông minh’ này, ta sẽ sống dễ dàng hơn trong không gian Internet mênh mông đầy bí ẩn.
Robot đá bóng và robot lái xe
RoboCup là một đề án nghiên cứu quốc tế từ 1995 nhằm phát triển TTNT, robot thông minh và các lĩnh vực liên quan. Chọn thi đấu bóng đá giữa các đội robot làm chủ đề nghiên cứu, đề án này hướng đến các sáng tạo công nghệ có nhiều ý nghĩa trong xã hội và công nghiệp. Với mục tiêu này, RoboCup đặt ra nhiều bài toán quan trọng đòi hỏi phải tích hợp nhiều công nghệ, như nguyên lý các tác tử tự trị, hợp tác đa tác tử, nhận biết chiến lược, lập luận thời gian thực, công nghệ robot, nhận dạng và xử lý các chuỗi hình ảnh liên tục trong thời gian thực, … Mục tiêu dài hạn của đề án RoboCup là đến năm 2050, sẽ làm được một đội người máy có thể thắng đội bóng đá vô địch thế giới. Một trong các ứng dụng chính của các công nghệ RoboCup là giải thoát nạn nhân trong các thảm họa. Có thể xem tin, hình ảnh và video của RoboCup tại http://www.robocup.org/.
Số người chết hằng năm ở Mỹ do tai nạn ôtô chỉ đứng sau số chết do bệnh tim và ung thư. Chế tạo được ôtô tự lái và an toàn cao là một mục tiêu được DARPA khởi xướng và hỗ trợ dưới dạng một cuộc thi mang tên ‘Thách thức lớn của DARPA’ (DARPA grand challenge). Cuộc thi cũng hướng đến sáng tạo các công nghệ tích hợp của thị giác máy, robot, lập kế hoạch tự động, học máy, lập luận,… để ôtô có thể tự chạy an toàn. Cuộc thi bắt đầu năm 2004 với yêu cầu xe tự đi 150 dặm qua sa mạc Nevada ở Mỹ. Có 106 đội tham gia, nhưng xe đi xa nhất chỉ được 7 dặm. Cuộc thi năm 2005 yêu cầu xe tự đi qua 132 dặm của sa mạc, đường khó hơn với hầm hẹp, dốc núi. Có 195 đội tham gia, và sau 6 giờ đua, hai đội của đại học Stanford và Carnegie Melon đã về nhất và nhì. Tháng 11.2007, cuộc thi chuyển qua lái trong thành phố với các vận động phức tạp như tránh xe khác, đỗ xe trong bãi, qua ngã tư, … tại Victorville, California với sự tham gia của 35 đội, thi qua nhiều vòng trong 8 ngày. Kết thúc cuộc đua, các đội của đại học Pittsburgh, Stanford, và Blackburg lần lượt giành các giải nhất, nhì và ba.
Sẽ đến một ngày, những chiếc ôtô chạy trên đường không cần người lái. Chỉ nói nơi muốn đến, xe sẽ đưa ta đi và đi an toàn.
TRÍ TUỆ NHÂN TẠO SẼ ĐI VỀ ĐÂU?
 |
Đây là câu hỏi không dễ trả lời, vì 50 năm qua ngành TTNT đã làm được rất nhiều và cũng không làm được rất nhiều những gì đã dự đoán. Dường như những người làm TTNT là những người lãng mạn nhất trong cộng đồng CNTT. Họ hay mơ ước, tưởng tượng và thách thức với những thứ của tương lai xa, và vì vậy cũng thường thất bại. Nhưng có điều to lớn nào khi đạt được lại không cần những con người như vậy?
Những bộ phim viễn tưởng của Hollywood hay tập trung vào người máy. Đấy thường là những người máy do con người trong một tương lai nào đấy tạo ra nhưng lại vượt ra khỏi tầm kiểm soát của con người, thay thế con người và thống trị thế giới. Hoặc như nếu đã xem bộ phim A.I. của Steven Spielberg mấy năm trước, hẳn ta không thể quên chú bé người máy David, tuy có trí tuệ nhân tạo vẫn luôn khát khao về một tình yêu của con người: “Mẹ ơi, hãy làm cho con thành một đứa trẻ thật”.
Những gì TTNT đang tạo ra ở đầu thế kỷ 21 này không làm con người phải sợ hãi, mà ngược lại đang từng bước đi vào cuộc sống hàng ngày của con người. Hiểu rõ về quá khứ, con người đang thiết kế và thực hiện những chương trình nghiên cứu lớn và định hướng, như khoa học về bộ não. Những gì Alan Turing nói năm 1950 vẫn có nghĩa trong thế kỷ 21 này: “Chúng ta chỉ có thể nhìn thấy một quãng đường ngắn trước mắt, nhưng chúng ta có thể thấy rất nhiều việc để làm”. Và với những gì con người đang làm, chúng ta có quyền nghĩ đến một ngày máy sẽ qua được phép thử Turing, trước khi TTNT đi hết chặng đường một thế kỷ.